Voici un schéma ultra-simple pour réaliser un oscillateur avec 2 transistors.
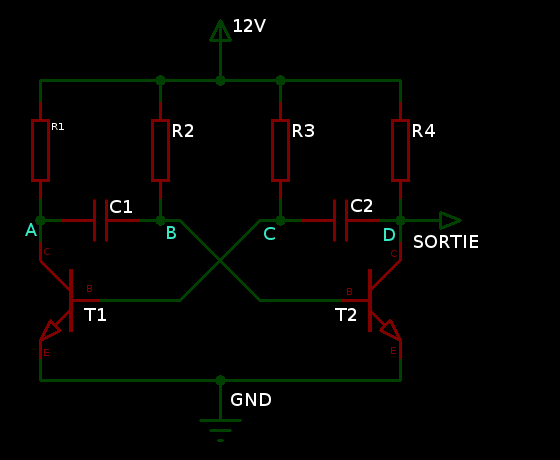
T1=T2=BC337 ou BC547 ou autre transistor NPN ordinaire comme le 2N2222
R1 et R4 et doivent être petits devant R2 et R3 mais suffisamment grands pour ne pas bruler les jonctions des transistors.
R2 et R3 doivent au moins être double de R1 et R4 pour ne pas écraser l’effet de commutation de capacités.
La fréquence du circuit est donné par la combinaison de deux temporisations : 1 pour chaque état
Tempo1 = R2 * C1 * ln(2)
Tempo2 = R3 * C2 * ln(2)
F = 1 / (Tempo1+Tempo2) = 1/( ln(2) * ( R2*C1 + R3*C2 ) )
Principe de Fonctionnement :
Prenons comme hypothèse qu’a un certain moment, C1 est déchargé (Uab=0) et que C2 est chargé à de façon a ce que Udc=+Vcc.
(Nous verrons dans un second temps comment on en arrive à cet état.)
Dans cet état, T2 est saturé par le courant traversant R1 et chargeant C1.
Cela fait que le point D est à sensiblement 0V (T2 est passant) et donc que le point C est donc a environ -Vcc via C2.
Il s’ensuit que T1 est bloqué (tension de base négative).
C2 se décharge progressivement via R3.
Le courant traversant R1 charge rapidement C1 en alimentant T2 jusqu’a ce que Uab atteigne Vcc. A ce moment là, le courant diminue et T2 tends à se bloquer.
Pendant ce temps, C2 se décharge (plus lentement) via R3
Quand la tension Udc s’annule, C1 a déjà atteint Vcc depuis quelques temps. Un courant commence à apparaitre sur la base de T1.
T1 devient passant ce qui entraine la baisse du potentiel A à une valeur proche de 0V et par là même celui de B à une valeur négative proche de -Vcc.
Cela finit immédiatement de bloquer T2.
Nous somme là dans l’état inverse de l’état initial.
Selon un raisonnement symétrique, C2 se recharge rapidement via R4 tandis que C1 se décharge plus lentement via R2.
Quand la tension Uab s’annule, C2 a déjà atteint Vcc depuis quelques temps. Un courant commence à apparaitre sur la base de T2.
T2 devient passant ce qui entraine la baisse du potentiel D à une valeur proche de 0V et par là même celui de C à une valeur négative proche de -Vcc qui bloque immédiatement T1.
Nous sommes revenu à l’état initial.
La boucle peut recommencer.
Maintenant comment en arrive-ton à cet état initial ?
La réponse est simple : à la mise sous tension les deux condensateurs sont déchargés et il existe un courant de charge via R1 et R4 qui rend passant les 2 transistors, lesquels devraient normalement abaisser les potentiels A et D ce qui forme une réaction négative. Cependant, dans ce circuit symétrique, il y aura toujours un déséquilibre entre les deux branches (capacité des condensateurs jamais identique et surtout écart de gain des transistors qui est naturellement assez important. Un des deux transistors va donc davantage bloquer l’autre et le cycle s’amorce.
Note : Il existe certainement des valeurs de de C et R pour lesquelles le circuit reste en équilibre stable, en particulier pour les fréquences élevées.
Générateur de tonalité
En général on veut un rapport cyclique de 1/2 ce qui fait qu’on prends C1 = C2 et R2 =R3
On a donc F = 1 / (2*Tempo) = 1/( 2 * ln(2) * R2*C1 )
Pour augmenter la fréquence on a donc le choix entre diminuer R2 ou C1 ou les deux.
Cependant R2 doit rester nettement supérieure à R1 laquelle ne doit pas être trop faible pour éviter de bruler les transistors.
Pour les basses fréquences, éviter de monter R2 trop au delà de 100k ohm car les fuites des condensateurs ne seraient plus négligeables.
C1 va de plusieurs milliers de microfarads à quelques nanofarads mais si on veut une fréquence assez stable, il vaut mieux éviter de descendre en dessous de 10nF.
Le montage est facilement perturbé par (ses propres) rayonnements électromagnétiques. On aura intérêt à minimiser au maximum les longueurs de fils entre les composants.


